

火车头采集列表地址过滤掉PHPSESSID的方法
最近发现网站用火车头采集的内容里有很多重复的内容。如下图,标题、内容都一样。但发布日期不一样。

采集器里面我明明设置检测重复网址了,如下图
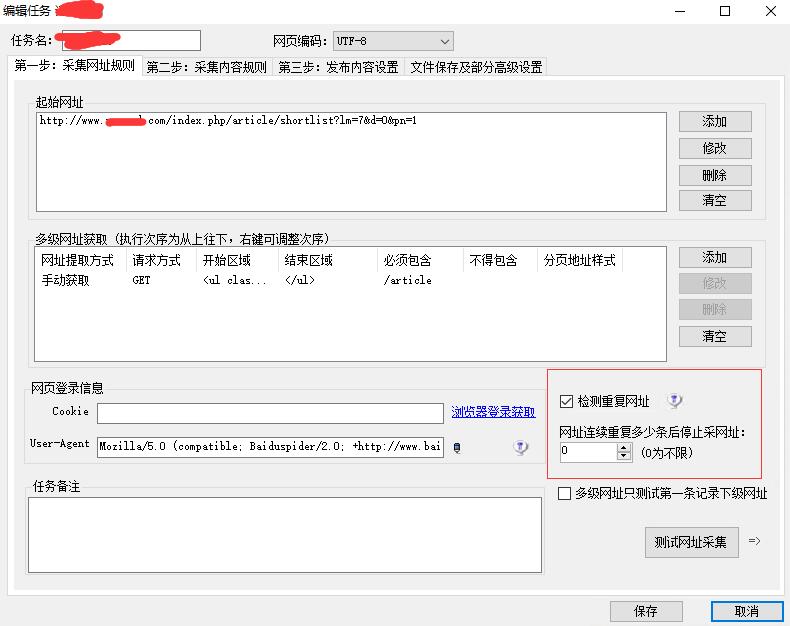
最后检查本地采集任务数据发现,采集页网址前面自动添加了?PHPSESSID=u3i1b955mq9864i3qa4j47h184这段字符。
如果直接通过浏览器访问的话,发现列表页的文章的地址是都是正常html地址,但通过采集器的话,获取的地址都会在.htm后面添加上?PHPSESSID=u3i1b955mq9864i3qa4j47h184这种字符。

并且这个字符是随机自动变。这样的话,就会出重复了。因为地址后面的PHPSESSID不一样,所以采集器就判断不出这篇文章是不是重复的。咨询官方,技术支持说用网址拼接,并给出规则 ,用她给的规则
结果测试不行。
经研究发现,地址是随机变的,这个可以当一个参数,但?PHPSESSID=这个是固定不变的,后面的数值又是随机的,可用(*)替换。一点测试,可以了。
文章的地址是:/article-900825.html?PHPSESSID=u3i1b955mq9864i3qa4j47h184
拼接地址如下:

然后测试网址。正常了。这样就不会出现重复的内容了。
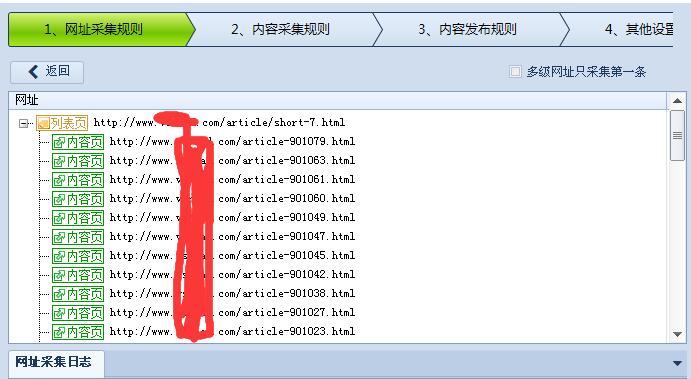
声明:
1.本站主要是为了记录工作、学习中遇到的问题,可能由于本人技术有限,内容难免有纰漏,一切内容仅供参考。
2.本站部分内容来源互联网,如果有图片或者内容侵犯您的权益请联系我们删除!
3.本站所有原创作品,包括文字、资料、图片、网页格式,转载时请标注作者与来源。
1.本站主要是为了记录工作、学习中遇到的问题,可能由于本人技术有限,内容难免有纰漏,一切内容仅供参考。
2.本站部分内容来源互联网,如果有图片或者内容侵犯您的权益请联系我们删除!
3.本站所有原创作品,包括文字、资料、图片、网页格式,转载时请标注作者与来源。
THE END
0
打赏
分享
二维码
海报